Performance analysis and explanation of cursor-based pagination as an alternative to the classic LIMIT + OFFSET pagination.
Summary
This document explains how to implement cursor-based pagination as an alternative to the traditional LIMIT + OFFSET pagination.
Problem Description
Pagination queries are common in relational databases, particularly when customers browse product catalogs.
In this document, we will not focus on query optimization—while that is always an important factor, it is outside the scope of this discussion.
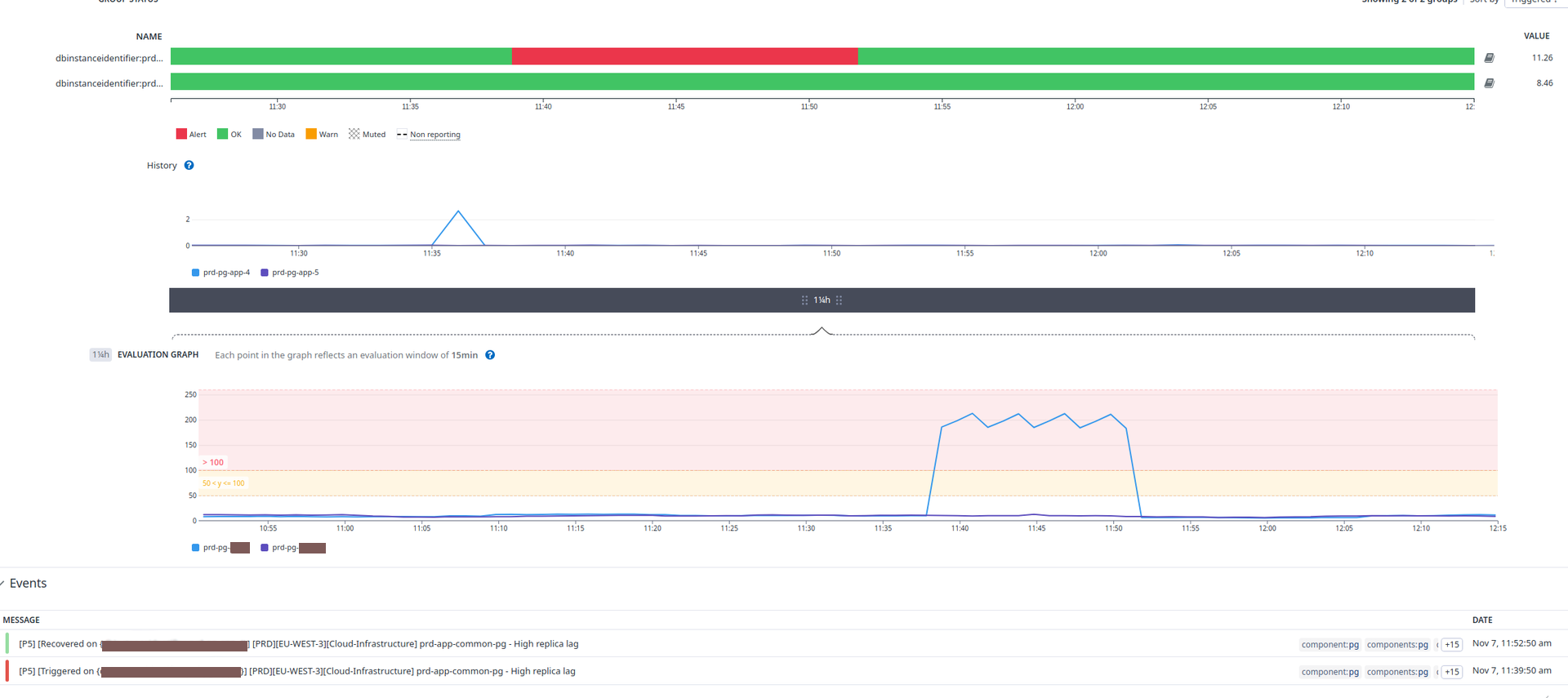
The issue arises with pagination: in PostgreSQL, as more pages are retrieved, resource consumption increases significantly.
Over time, this leads to performance degradation, potentially affecting the entire cluster.
Due to the way a PostgreSQL cluster operates, this behavior can contribute to “Replica Lag,” impacting overall system performance.
What is Cursor-Based Pagination?
Cursor-based pagination is an alternative to the traditional LIMIT + OFFSET approach, designed to improve efficiency when paginating large datasets.
Instead of skipping a fixed number of rows, it uses a cursor—a reference to a specific position in the dataset—allowing the next page to be retrieved based on this reference.
This method significantly reduces performance overhead since the database doesn’t have to scan and discard rows before returning results.
It’s widely used in high-performance applications to minimize query execution time and resource consumption.
A real live problem
Limit+Offset Query
This is the original query (slightly modified for privacy):
SELECT
view.sku,
title,
image,
...,
stock,
COALESCE(available_stock, stock) AS available_stock,
available_stock_updated_at,
...,
om_offer_id
FROM (
SELECT
*
FROM
seller_catalog.extra_data
WHERE
seller_contract_id = ?
AND status = ?
ORDER BY
sku
LIMIT ? OFFSET ?)
VIEW
JOIN (
SELECT
seller_contract_id,
sku,
...
stock,
...
FROM
seller_catalog.offer
WHERE
seller_contract_id = ?
ORDER BY
sku) io ON io.seller_contract_id = view.seller_contract_id
AND io.sku = view.sku
ORDER BY
sku;
Nothing special at first glance—indexes are being used, and response time is good, but it was still causing issues and replica lag:
Query plan summary for offset-based pagination
Limit (cost=93579.52..93580.68 rows=10 width=769) (actual time=234.355..240.666 rows=10 loops=1)
" Output: scpi.sku, scpi.hidden...
" Buffers: shared hit=69962, temp read=3866 written=3962"
-> Gather Merge (cost=87162.40..93767.60 rows=56612 width=769) (actual time=173.211..237.499 rows=55010 loops=1)
" Output: scpi.sku, scpi.hidden...
Workers Planned: 2
Workers Launched: 2
" Buffers: shared hit=69962, temp read=3866 written=3962"
-> Sort (cost=86162.38..86233.14 rows=28306 width=769) (actual time=163.165..177.751 rows=18427 loops=3)
" Output: scpi.sku, scpi.hidden...
Sort Key: scpi.sku
Sort Method: external merge Disk: 11520kB
" Buffers: shared hit=69962, temp read=3866 written=3962"
Worker 0: actual time=154.595..167.976 rows=16896 loops=1
Sort Method: external merge Disk: 9544kB
" Buffers: shared hit=22340, temp read=1178 written=1196"
Worker 1: actual time=162.071..176.828 rows=18265 loops=1
Sort Method: external merge Disk: 10560kB
" Buffers: shared hit=24062, temp read=1307 written=1323"
-> Parallel Seq Scan on seller_catalog_cooker.seller_catalog_8 scpi (cost=0.00..74391.82 rows=28306 width=769) (actual time=0.015..87.886 rows=23676 loops=3)
" Output: scpi.sku, scpi.hidden...
Filter: (scpi.seller_contract_id = 12)
Rows Removed by Filter: 267544
Buffers: shared hit=69842
Worker 0: actual time=0.009..85.074 rows=21420 loops=1
Buffers: shared hit=22280
Worker 1: actual time=0.011..88.314 rows=23690 loops=1
Buffers: shared hit=24002
Planning Time: 0.183 ms
Execution Time: 244.012 ms
Cursor-based query
Next, the cursor-based query:
SELECT
view.sku,
title,
image,
...,
stock,
COALESCE(available_stock, stock) AS available_stock,
available_stock_updated_at,
...,
om_offer_id
FROM (
SELECT
*
FROM
seller_catalog.extra_data
WHERE
seller_contract_id = ?
AND status = ?
AND SKU = :LAST_SKU_IN_SERIE
ORDER BY
sku
LIMIT 60)
VIEW
JOIN (
SELECT
seller_contract_id,
sku,
...
stock,
...
FROM
seller_catalog.offer
WHERE
seller_contract_id = ?
ORDER BY
sku) io ON io.seller_contract_id = view.seller_contract_id
AND io.sku = view.sku
ORDER BY
sku;
Query plan summary for cursor-based pagination
Limit (cost=0.42..44.19 rows=10 width=769) (actual time=6.721..6.745 rows=10 loops=1)
" Output: scpi.sku, scpi.hidden...
Buffers: shared hit=13 read=3
I/O Timings: read=6.632
-> Index Scan using seller_catalog_8_pkey on seller_catalog.seller_catalog_8 scpi (cost=0.42..17840.39 rows=4076 width=769) (actual time=6.720..6.743 rows=10 loops=1)
" Output: scpi.sku, scpi.hidden...
Index Cond: (((scpi.sku)::text >= 'SAM01306'::text) AND (scpi.seller_contract_id = 12))
Buffers: shared hit=13 read=3
I/O Timings: read=6.632
Planning:
Buffers: shared hit=5
Planning Time: 0.196 ms
Execution Time: 6.773 ms
Stress Test Results
Our initial look at the results was not very impressive—visually, we only observed an improvement of ~100ms per request.
However, when analyzing the data as a graph, the problem becomes evident, along with the potential for optimization.
In the following graph:
- OFFSET represents the current pagination system.
- SKU represents cursor-based pagination.

As shown in the graph, OFFSET-based pagination continues to grow in execution time, while cursor-based pagination slightly decreases.
Over time, the gap between the two methods keeps widening.
This behavior also affects all resources in the cluster—longer query times lead to higher CPU, memory, and network consumption.
Suggestions
To handle customer’s ever-growing data platform, we must find efficient ways to manage it.
Cursor-based pagination is a widely adopted best practice, especially in platforms like marketplaces.
At OneClickDBA, we specialize in database optimization and performance tuning.
Our expertise ensures that your data platform scales efficiently, minimizing issues like replica lag and resource overconsumption.